


by Rachel Thomas and Marianne Freiberger
伝染病の実効再生産数Rは,母集団の異なる部分で異なる値を持つ可能性があります.Rは,感染した人が他に感染させる平均人数でした.社会のさまざまな部分(たとえば,地理的区分,病院や介護施設など)ごとに,R値が異なる場合は,これらのさまざまな構成要素がどのように結びついているかを考慮する必要があります.ご想像のとおり,これにより計算が複雑になります.それでは,その数学をさらに詳しく見てみましょう.
その記事の例を続けましょう.人口を2つのグループに分割したものを検討します.介護施設や病院の患者またはスタッフなどの「病院」というラベルのグループと,残りの人口の「コミュニティ」と呼ばれるグループです.コミュニティのRは0.8,病院のRは0.7としましょう.
これら2つのグループを独立個別なものとして検討することはできません.コミュニティの人々が病気になったときは病院に移動するし,病院や介護施設のスタッフが無意識のうちにウイルスをコミュニティに持ち込むことがありえます.これら2つのグループ間の病気の伝染を考慮する必要があります.仮定として,コミュニティでの感染が続いてかつ病院で0.4の新しい感染を引き起こし,病院での感染が続いてかつコミュニティで0.2の新しい感染を引き起こすとしましょう.これで,病院およびコミュニティに関して,それぞれの内部と両者間での感染で4種類があることがわかりました.

■病院に1000人の感染者がいて,地域社会に1000人の感染者がいる場合,新しい感染例はどれほど発生しますか?
有用な発見と警告
数学的詳細に入る前に,例を見て,表から直接読み取れる情報を確認しましょう.左側の列の数値を合計すると1.2になります.これは,コミュニティの感染者が平均して感染させる人の総数です.そして,右側の列の数値を合計すると0.9になります.これは,病院で感染した人が平均して感染させる人の総数です.このようなテーブルの列の数値を単純に合計すると,状況によって,起こっていることの有用なヒントが得られます.
列の合計が両方とも1未満になる場合:列内の数を合計すると,両方の列で1未満になる場合,つまり,平均して1人未満の人が感染することになります.全体のR値が常に1未満になることを示しており,この病気が制御されていることになります.
列の合計が両方とも1を超える場合,各列の合計が1を超える場合,すべての列について,つまり,すべての感染が平均して複数の人に感染することになります.全体のR値が常に1より大きいことを数学的に示すことができ,病気の新しい感染が指数関数的に増加することになります.
列の1つが1を超え,列の1つが1未満の場合,難しい状況になります.この状況では,全体のRを計算して,疾患が制御下にあるのか,制御不能なのかを知るには,数学の知識が必要になります.例題は,この場合です.
世代を超えて
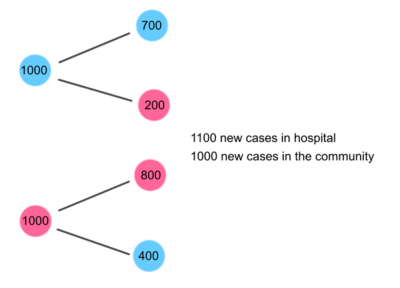
この例で,もう少し数学の詳細を説明します.コミュニティの元の感染者数には$$ I_ c(0)= 1000 $$,病院の元の感染者数には$$ I_ h(0)= 1000 $$の記号を使用します. 1つのグループの第1世代の新しい感染を計算するには,そのグループ内で生成された新しい感染の数(つまり,元のコミュニティ感染によって引き起こされた新しいコミュニティ内感染$$ R_ {cc} I_ c(0)= 800 $$)と,他のグループからの新しい感染の数(つまり、病院での元の感染によって引き起こされた新しいコミュニティ感染$$ R_ {hc} I_ h(0)= 200 $$)が必要です.次に,コミュニティの第1世代の新しい感染,$$ I_ c(1)$$,および病院の$$ I_ h(1)$$の計算は次のとおりです.
$$I_{c}(1)=R_{cc}I_{c}(0)+R_{hc}I_{h}(0)=800+200=1000$$
$$I_{h}(1)=R_{ch}I_{c}(0)+R_{hh}I_{h}(0)=400+700=1100$$
fig
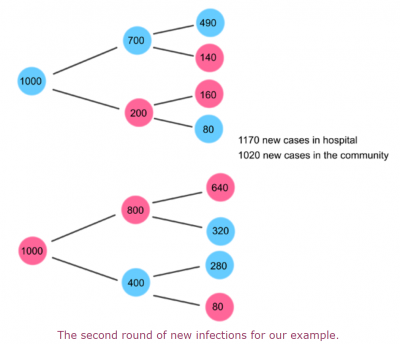
$$I_{c}(2)=R_{cc}I_{c}(1)+R_{hc}I_{h}(1)=800+220=1020$$
$$I_{h}(2)=R_{ch}I_{c}(1)+R_{hh}I_{h}(1)=400+770=1170$$
fig
このようにして,未来の世代に対して順次計算を進めることができます.
中間のステップをして,初期状態の感染数でn世代の感染数を記述するのが効率的です.
$$ I_{c}(2)=R_{cc}I_{c}(1)+R_{hc}I_{h}(1) =R_{cc}(R_{cc}I_{c}(0)+R_{hc}I_{h}(0))+R_{hc}(R_{ch}I_{c}(0)+R_{hh}I_{h}(0))$$
$$=(R_{cc}^{2}+R_{ch}R_{hc})I_{c}(0)+(R_{hc}R_{cc}+R_{hh}R_{hc})I_{h}(0) $$
$$ I_{h}(2)=R_{ch}I_{c}(1)+R_{hh}I_{h}(1) =R_{ch}(R_{hc}I_{h}(0)+R_{cc}I_{c}(0))+R_{hh}(R_{hh}I_{h}(0)+R_{ch}I_{c}(0))$$
$$=(R_{ch}R_{hh}+R_{cc}R_{ch})I_{c}(0) +(R_{hh}^{2}+R_{hc}R_{ch})I_{h}(0)$$
$$ \left( \begin{array}{@{\,} c @{\, } } I_{c}(1) \\[0mm] I_{h}(1) \end{array} \right) =\left( \begin{array}{@{\,} cc @{\, } } R_{cc} & R_{hc} \\[0mm] R_{ch} & R_{hh} \end{array} \right) \left( \begin{array}{@{\,} c @{\, } } I_{c}(0) \\[0mm] I_{h}(0) \end{array} \right) =\left( \begin{array}{@{\,} c @{\, } } R_{cc}I_{c}(0)+R_{hc}I_{h}(0) \\[0mm] R_{ch}I_{c}(0)+R_{hh}I_{h}(0) \end{array} \right) $$
$$\left( \begin{array}{@{\,} c @{\, } }
I_{c}(2) \\[0mm]
I_{h}(2)
\end{array} \right) =\left( \begin{array}{@{\,} cc @{\, } }
R_{cc} & R_{hc} \\[0mm]
R_{ch} & R_{hh}
\end{array} \right) \left( \begin{array}{@{\,} c @{\, } }
I_{c}(1) \\[0mm]
I_{h}(1)
\end{array} \right) =\left( \begin{array}{@{\,} cc @{\, } }
R_{cc} & R_{hc} \\[0mm]
R_{ch} & R_{hh}
\end{array} \right) \left( \begin{array}{@{\,} cc @{\, } }
R_{cc} & R_{hc} \\[0mm]
R_{ch} & R_{hh}
\end{array} \right) \left( \begin{array}{@{\,} c @{\, } }
I_{c}(0) \\[0mm]
I_{h}(0)
\end{array} \right) $$
$$\left( \begin{array}{@{\,} c @{\, } }
I_{c}(n) \\[0mm]
I_{h}(n)
\end{array} \right) =\left( \begin{array}{@{\,} cc @{\, } }
R_{cc} & R_{hc} \\[0mm]
R_{ch} & R_{hh}
\end{array} \right) \left( \begin{array}{@{\,} c @{\, } }
I_{c}(n-1) \\[0mm]
I_{h}(n-1)
\end{array} \right) =\left( \begin{array}{@{\,} cc @{\, } }
R_{cc} & R_{hc} \\[0mm]
R_{ch} & R_{hh}
\end{array} \right) ^{n}\left( \begin{array}{@{\,} c @{\, } }
I_{c}(0) \\[0mm]
I_{h}(0)
\end{array} \right) $$
$$I(n)=MI(n-1)=M^{n}I(0)$$
(訳者注)
$$PMP^{-1}=\left( \begin{array}{@{\,} cc @{\, } }
\lambda _{1} & 0 \\[0mm]
0 & \lambda _{2}
\end{array} \right) $$と対角化できれば,$$PM^{n}P^{-1}=\left( \begin{array}{@{\,} cc @{\, } }
\lambda _{1}^{n} & 0 \\[0mm]
0 & \lambda _{2}^{n}
\end{array} \right) $$
全体のRは?
線形代数を使用すると,伝染病の成長をより明確かつエレガントに表現できます.
たとえば、次世代マトリックス$$ M $$の固有値と呼ばれるものを見つけることができます.これらは2つの数値$$ \lambda _1 $$と$$ \lambda _2 $$であり,対応する固有ベクトル$$ v_1 $$と$$ v_2 $$があるため,行列による固有ベクトルは,固有値倍だけ拡大されます.
$$Mv_ i = \lambda _ i v_ i $$
そして、誘導で示すことができ、固有ベクトルに$ M $を繰り返し適用すると、次のようになります。
$$ M ^ k v_ i = \lambda _ i ^ k v_ i $$
もう1つの有用な線形代数の事実は、ほぼすべての行列で、固有ベクトルが線形に独立していることです。これは、1つの固有ベクトルが他の固有ベクトルではないことを意味します。そして実際、これらの2つの固有ベクトルの線形結合として任意のベクトルを書くことができます。 (この事実を真実にするには、固有値と固有ベクトルに複素数を許可する必要があります。詳細はこちらで読むことができますが、これについては気にしない理由を少し後で明らかにします。)
つまり、コミュニティと病院の元の感染数で構成される感染ベクトル$$ I(0)$$を次のように記述できます。
$$ I(0)= av_1 + bv_2 $$
次に、次世代の新しい感染症は次のようになります。
$$I(1)= MI(0)= aMv_1 + bMv_2 = a \lambda _1v_1 + b \lambda _2v_2$$
そして、新しい感染の$$ n $$世代は次のようになります。
$$I(n)= M ^ nI(t)= a \lambda _1 ^nv_1 + b \lambda _2 ^ nv_2$$
線形代数からの別の結果によると、次世代行列のエントリはすべて正の実数であるため(負の数に感染させることはできません)、(大きさの点で)「最大」の固有値もaになります。正の実数。私たちはみな指数関数的成長に精通しているので、世代数が増えるにつれて,$$I(n)$$の式がその支配的な固有値を含む項によってどのように支配されるかがわかります。
実際、この支配的な固有値が、そのような次世代行列で表される区分化されたシステムのRの全体的な値と同等であることを示すことができます。そして最終的に、システムは、対応する固有ベクトルによって表される2つの設定間の感染の分割に落ち着きます。
$$ \left( \begin{array}{@{\,} cc @{\, } } 0.8 & 0.2 \\[0mm] 0.4 & 0.7 \end{array} \right) $$
この例では、次世代行列の固有値
1.04と0.46(小数点以下2桁に四捨五入)です。したがって、この区分された母集団の全体的なRはR = 1.04です。そして、何世代にもわたる感染症の後、新しい感染症の約45%が地域社会で発生し、新しい感染症の55%が病院で発生します。 (これは、支配的な固有ベクトルが(0.84、1)であり、1.84のうちで0.84が45%,1が55%ですからわかります)
Rでわかること
この例では、人口を2つのグループに分けています。病院(介護施設を含む)とコミュニティです。しかし、介護施設、病院、地域社会など、より多くのグループを区別したい場合はどうでしょうか。または、いくつかの地理的地域間で?数学は、任意の数のグループに分割された母集団に拡張できます。次世代マトリックス(モデルでは2x2)の次元はグループの数まで増加し、グループのいずれか2つの間の感染の伝達のエントリと、各グループ内で生成された感染の個々のR値が含まれます。そして、上で紹介した数学は今でも機能し、全母集団の全体的なRは次世代行列の主要な固有値です。
前の記事で直感的に調査したように、区分化された母集団の全体的なRの値は、次世代行列の個々の数値の値よりも常に大きくなります。これは、任意の数のグループに分割された母集団について数学的に証明できます。支配的な固有値である全体のRの計算は、線形代数を使用すると簡単ですが、頭の中で行うのは簡単ではありません。上の図の例で示したように、グループ間およびグループ内の透過率の値がすべて1未満であっても、覚えておくべき重要なことは、全体のRが1より大きい場合があることです。確実に計算する必要があります。